using DataFrames
using DataFramesMeta
using Panelest
using Vcov
using StatsModels
import StatsAPI: coeftable
using ReadStatTables
using CSV
using SynthDiD
using CairoMakie
using Statistics
using Printf
using RegressionTables
using Random
using Distributions13 Difference-in-Differences
What if unconfoundedness fails? We have to settle for weaker assumptions. One such assumption is the parallel trends assumption. If we have this assumption, we can use a difference-in-differences estimator.
Related reading: For a side-by-side comparison of DiD, synthetic control, synthetic DiD, and multivariate SC on a single panel — and how the choice of estimator changes the answer — see the Same data, different estimators chapter of Topics on Econometrics and Causal Inference.
13.1 \(T=2\) Panel Data
Suppose we have two periods, \(t = (1,2)\). Some units are treated just prior to period 2. For each individual \(i\), there are four potential outcomes:
\[ [Y_{i1}(0), Y_{i1}(1), Y_{i2}(0), Y_{i2}(1)] \]
We use \(D\) to identify the treated group.
The ATT when \(T=2\):
\[ \tau_{2,att} = E(Y_2(1) - Y_2(0) | D=1) \]
In words, we are interested in the ATT in the second period. The difficult part is the second term.
13.2 Parallel Trends Assumption
\[ E[Y_2(0) -Y_1(0) | D=1] = E[Y_2(0) - Y_1(0) | D =0] \]
or
\[ E[\Delta Y(0) | D=1] = E[\Delta Y(0) | D =0] \]
In other words, this means the change of potential outcome for untreated state between period 1 and 2 is independent of treatment assignment (unconfounded).
13.3 No Anticipation Assumption
\[ E[Y_1(1) - Y_1(0) | D=1] = 0 \]
This is to say, in period 1, there is no treatment effect for the treated group.
13.4 DiD is Identified with PT and NA
With Parallel Trends, we notice \[\small E[Y_2(0) | D=1 ]= E[Y_1(0) | D=1] + E[Y_2(0) - Y_1(0) | D=0] \]
Then, with No Anticipation, \[\small \begin{align} E[Y_2(0) | D=1 ] &= E[Y_1(1) | D=1] + E[Y_2(0) - Y_1(0) | D=0]\\ &= E[Y_1 | D=1] + E[Y_2-Y_1 | D=0] \end{align} \]
\[\small \tau_{2,att} = E[Y_2 - Y_1 | D=1] - E[Y_2-Y_1 | D=0] \]
13.5 Advantages and Disadvantages of DiD
Advantages:
- No need to assume unconfoundedness. We “only” need PT and NA. Or say we don’t need treatment itself to be independent of potential outcomes, but we do need it to be independent to the change in potential outcome at least for untreated state. This is importantly weaker in a lot of situations. There can be selection bias. If the selection bias does not change over time, then DiD can handle it.
Disadvantages:
- PT and NA might be violated.
- PT is not scale free, in the sense that even if outcome can have PT, but then non-linear transformation of outcome won’t have PT (for example log of Y).
13.6 Traditional DiD
In practice, DiD in many period setting is usually done with
\[ Y_{it} = \alpha_i + \phi_t + W_{it} \beta + \epsilon_{it} \]
here \(W_{it} =(1[t=2] \cdot D_i)\), which is the interaction of post-treatment indicator and treatment group indicator.
This is usually called Two Way Fixed Effect (TWFE). There are multiple ways to implement the same model in practice.
TWFE can be done by “Pooled OLS”. That is, using OLS on time dummies and firm (individual) dummies. Wooldridge (2021) shows it’s equivalent to use treatment dummies, instead of individual dummies. He also shows that this model can be equivalently implemented with fixed effect model and random effect model.
13.7 TWFE with Staggered Treatment Timing
The problem comes in when there is different timing of treatment. People used to still use
\[ Y_{it} = \alpha_i + \phi_t + W_{it} \beta + \epsilon_{it} \]
where \(W_{it}\) now is a dummy when an individual \(i\) gets treated at time \(t\).
However, what is \(\beta\) here?
13.8 Goodman-Bacon Decomposition
Goodman-Bacon (2021) showed that \(\beta\) in the TWFE is a weighted average of many different treatment effects, between treated cohorts, and control units, both can be different at different time points. The weights are a function of the size of the subsample, relative size of treatment and control units, and the timing of treatment in the sub sample. The decomposition weights themselves are non-negative and sum to one; the problem is that the units treated earlier are used as controls later. When those “forbidden” 2x2 comparisons are expressed in terms of the underlying cohort-time ATTs, some ATTs receive negative weight (de Chaisemartin and D’Haultfœuille 2020). Therefore there is no meaningful interpretation of \(\beta\): it does not need to be a convex combination of treatment effects.
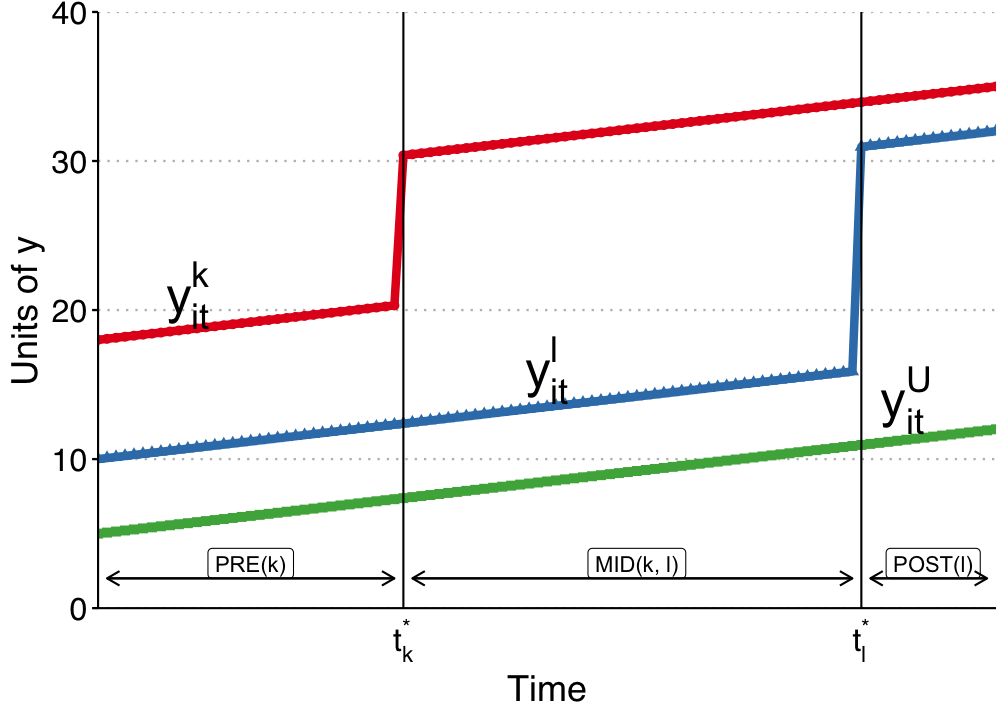
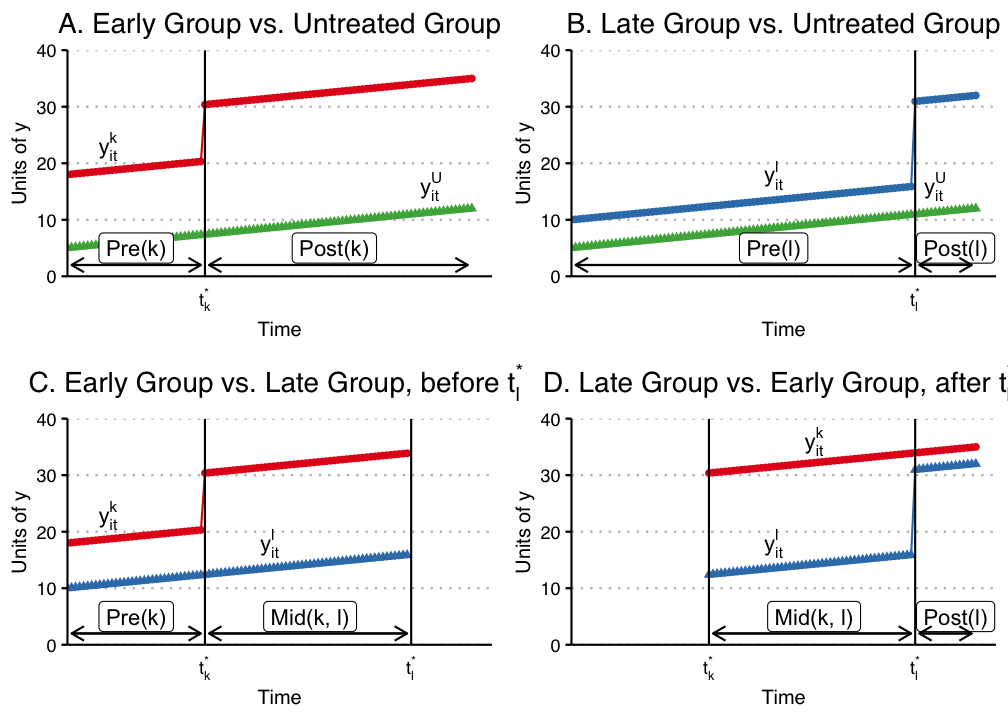
13.9 Wooldridge’s ETWFE
There are a lot of ways to deal with staggered DiD situation. Wooldridge (2021) is basically saying: This is not a problem of TWFE, it’s a mis-use of TWFE. The reason we get non-sensible result of \(\beta\) is that we know there is heterogeneous treatment effect, in the sense the treatment effect differs across cohort, but we force them to be the same. If we relax it, it can work. As he shows, this works when we specify cohort effects accordingly.
\[ y_{it} = \alpha_i + \phi_t + \sum_{g=g_0}^G \sum_{t=g}^T \lambda_{g,t} \times 1(g,t) + \epsilon_{i,t} \]
Here \(g\) is a cohort indicator, a cohort is determined by the time of getting treatment. ETWFE is allowing each cohort to have different effect at each different time point after being treated. The baseline group is the never treated group. If there is no never treated group, it can easily changed to comparing to the last treated group.
13.10 Example 1: US Teen Employment
We’ll use the mpdta dataset on US teen employment from the did package. “Treatment” in this dataset refers to an increase in the minimum wage rate. Our goal is to estimate the effect of this minimum wage treatment (treat) on the log of teen employment (lemp). Notice that the panel ID is at the county level (countyreal), but treatment was staggered across cohorts (first_treat) so that a group of counties were treated at the same time. In addition to these staggered treatment effects, we also observe log population (lpop) as a potential control variable.
# Load mpdta dataset from the did R package (Callaway & Sant'Anna 2021)
# US teen employment data; treatment = minimum wage increase
mpdta = CSV.read("data/mpdta.csv", DataFrame)
rename!(mpdta, "first.treat" => "first_treat")
first(mpdta, 6)6×6 DataFrame
| Row | year | countyreal | lpop | lemp | first_treat | treat |
|---|---|---|---|---|---|---|
| Int64 | Int64 | Float64 | Float64 | Int64 | Int64 | |
| 1 | 2003 | 8001 | 5.89676 | 8.46147 | 2007 | 1 |
| 2 | 2004 | 8001 | 5.89676 | 8.33687 | 2007 | 1 |
| 3 | 2005 | 8001 | 5.89676 | 8.34022 | 2007 | 1 |
| 4 | 2006 | 8001 | 5.89676 | 8.37816 | 2007 | 1 |
| 5 | 2007 | 8001 | 5.89676 | 8.48735 | 2007 | 1 |
| 6 | 2003 | 8019 | 2.23238 | 4.99721 | 2007 | 1 |
combine(groupby(mpdta, :year), nrow)
combine(groupby(mpdta, :treat), nrow)
combine(groupby(mpdta, :first_treat), nrow)4×2 DataFrame
| Row | first_treat | nrow |
|---|---|---|
| Int64 | Int64 | |
| 1 | 0 | 1545 |
| 2 | 2004 | 100 |
| 3 | 2006 | 200 |
| 4 | 2007 | 655 |
# String columns enable StatsModels to generate cohort×time dummies (ETWFE)
mpdta.first_treat_str = string.(mpdta.first_treat)
mpdta.year_str = string.(mpdta.year)
mod = feols(mpdta, @formula(lemp ~ lpop + first_treat_str & year_str + fe(countyreal) + fe(year)), vcov = Vcov.cluster(:countyreal))Panelest Model: ols
Number of obs: 2500
Converged: true
Iterations: 1
StatsBase.CoefTable(Any[[-3.4135316702287624e-33, -0.016068364858818695, 0.047730936400964666, -0.0104701478480778, -0.02119242369406829, -0.022699245305459644, 0.0305968097333614, -0.01058091587048539, 0.0026833514425835467, -0.00635008942575461 … 0.0030174212587004232, 0.016306614436172342, 0.01927923735644746, -0.054180200273172406, 0.02405214108803968, 0.010848821828685481, 0.02583846223358552, -0.011173599592035538, -0.006018498628176904, -0.008646364013373136], [2.693734919824209e-33, 0.010078316236422944, 0.01595288409731988, 0.017137025099277562, 0.011759676186809464, 0.007612886466273422, 0.013915644744225132, 0.00989279226068868, 0.008805267304217107, 0.006488322802137784 … 0.009240983616431102, 0.007952522630443234, 0.008259811231470142, 0.013273467701922963, 0.010176640147651453, 0.009275934764944458, 0.009151011027330144, 0.015526030036024176, 0.012651681503127534, 0.011287368047456251], [-1.2672114264500558, -1.5943501356652978, 2.991994181728154, -0.6109664768197828, -1.802126466529691, -2.9816870914891145, 2.198734610989462, -1.0695580774025883, 0.30474389361222565, -0.9786950525430658 … 0.3265259829413875, 2.050495823017041, 2.334101448104886, -4.081842174921869, 2.363465813772573, 1.1695664214549315, 2.823563664869064, -0.7196688120601379, -0.47570740906567344, -0.7660212705938744], [0.20507970114688281, 0.11085763425089842, 0.0027716154538513574, 0.5412217737289009, 0.07152551052359446, 0.0028666482948026565, 0.02789679840386153, 0.28481827388510017, 0.7605612164012949, 0.32773067736526 … 0.7440264340669105, 0.04031607098319924, 0.019590410497807256, 4.4680135143972516e-5, 0.01810489696348593, 0.24217549685092654, 0.004749299250498021, 0.4717289331182837, 0.6342828417802775, 0.4436636459744491]], ["Estimate", "Std. Error", "z value", "Pr(>|z|)"], ["lpop", "first_treat_str: 0 & year_str: 2003", "first_treat_str: 2004 & year_str: 2003", "first_treat_str: 2006 & year_str: 2003", "first_treat_str: 2007 & year_str: 2003", "first_treat_str: 0 & year_str: 2004", "first_treat_str: 2004 & year_str: 2004", "first_treat_str: 2006 & year_str: 2004", "first_treat_str: 2007 & year_str: 2004", "first_treat_str: 0 & year_str: 2005" … "first_treat_str: 2006 & year_str: 2005", "first_treat_str: 2007 & year_str: 2005", "first_treat_str: 0 & year_str: 2006", "first_treat_str: 2004 & year_str: 2006", "first_treat_str: 2006 & year_str: 2006", "first_treat_str: 2007 & year_str: 2006", "first_treat_str: 0 & year_str: 2007", "first_treat_str: 2004 & year_str: 2007", "first_treat_str: 2006 & year_str: 2007", "first_treat_str: 2007 & year_str: 2007"], 4, 3)show_regression_html(mod)| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| lpop | -3.414e-33 | 2.694e-33 | -1.267 | 0.205 |
| first_treat_str: 0 & year_str: 2003 | -0.016 | 0.010 | -1.594 | 0.111 |
| first_treat_str: 2004 & year_str: 2003 | 0.048 | 0.016 | 2.992 | 0.003 ** |
| first_treat_str: 2006 & year_str: 2003 | -0.010 | 0.017 | -0.611 | 0.541 |
| first_treat_str: 2007 & year_str: 2003 | -0.021 | 0.012 | -1.802 | 0.072 . |
| first_treat_str: 0 & year_str: 2004 | -0.023 | 0.008 | -2.982 | 0.003 ** |
| first_treat_str: 2004 & year_str: 2004 | 0.031 | 0.014 | 2.199 | 0.028 * |
| first_treat_str: 2006 & year_str: 2004 | -0.011 | 0.010 | -1.070 | 0.285 |
| first_treat_str: 2007 & year_str: 2004 | 0.003 | 0.009 | 0.305 | 0.761 |
| first_treat_str: 0 & year_str: 2005 | -0.006 | 0.006 | -0.979 | 0.328 |
| first_treat_str: 2004 & year_str: 2005 | -0.013 | 0.010 | -1.244 | 0.214 |
| first_treat_str: 2006 & year_str: 2005 | 0.003 | 0.009 | 0.327 | 0.744 |
| first_treat_str: 2007 & year_str: 2005 | 0.016 | 0.008 | 2.050 | 0.040 * |
| first_treat_str: 0 & year_str: 2006 | 0.019 | 0.008 | 2.334 | 0.020 * |
| first_treat_str: 2004 & year_str: 2006 | -0.054 | 0.013 | -4.082 | 4.468e-05 *** |
| first_treat_str: 2006 & year_str: 2006 | 0.024 | 0.010 | 2.363 | 0.018 * |
| first_treat_str: 2007 & year_str: 2006 | 0.011 | 0.009 | 1.170 | 0.242 |
| first_treat_str: 0 & year_str: 2007 | 0.026 | 0.009 | 2.824 | 0.005 ** |
| first_treat_str: 2004 & year_str: 2007 | -0.011 | 0.016 | -0.720 | 0.472 |
| first_treat_str: 2006 & year_str: 2007 | -0.006 | 0.013 | -0.476 | 0.634 |
| first_treat_str: 2007 & year_str: 2007 | -0.009 | 0.011 | -0.766 | 0.444 |
| --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 |
||||
emfx(mod)1×5 DataFrame
| Row | type | estimate | std_error | conf_low | conf_high |
|---|---|---|---|---|---|
| String | Float64 | Float64 | Float64 | Float64 | |
| 1 | ATT | -0.00547767 | 0.00252612 | -0.0104288 | -0.000526576 |
mod_es = emfx(mod, type = "event")
mod_es4×5 DataFrame
| Row | event | estimate | std_error | conf_low | conf_high |
|---|---|---|---|---|---|
| Int64 | Float64 | Float64 | Float64 | Float64 | |
| 1 | 0 | 0.0153342 | 0.00778068 | 8.43689e-5 | 0.030584 |
| 2 | 1 | -0.00949622 | 0.0079286 | -0.025036 | 0.00604351 |
| 3 | 2 | -0.0541802 | 0.0132735 | -0.0801957 | -0.0281647 |
| 4 | 3 | -0.0111736 | 0.015526 | -0.041604 | 0.0192568 |
mod_es2 = emfx(mod, type = "event", post_only = false)
fig = Figure()
ax = Axis(fig[1, 1],
xlabel = "Years post treatment",
ylabel = "Effect on log teen employment",
title = "Note: Zero pre-treatment effects for illustrative purposes only.")
hlines!(ax, 0, color = :black)
vlines!(ax, -1, color = :black, linestyle = :dash)
rangebars!(ax, mod_es2.event, mod_es2.conf_low, mod_es2.conf_high, color = :darkcyan)
scatter!(ax, mod_es2.event, mod_es2.estimate, color = :darkcyan)
fig
13.11 Example 2: Staggered DiD
did_data = DataFrame(readstat("data/did_staggered_6.dta"))
@rtransform! did_data :first_treat = begin
if :d4 == 1
2004
elseif :d5 == 1
2005
elseif :d6 == 1
2006
else
0
end
end
first(select(did_data, :id, :year, :y, :x, :d4, :d5, :d6, :te4, :te5, :te6, :first_treat), 6)6×11 DataFrame
| Row | id | year | y | x | d4 | d5 | d6 | te4 | te5 | te6 | first_treat |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Int16 | Int16 | Float32 | Float32 | Int8 | Int8 | Int8 | Float32 | Float32 | Float32 | Int64 | |
| 1 | 1 | 2001 | 18.3596 | 0.899984 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0 |
| 2 | 1 | 2002 | 18.1016 | 0.899984 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0 |
| 3 | 1 | 2003 | 18.5956 | 0.899984 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0 |
| 4 | 1 | 2004 | 16.5003 | 0.899984 | 0 | 0 | 0 | 1.43223 | 0.0 | 0.0 | 0 |
| 5 | 1 | 2005 | 19.9573 | 0.899984 | 0 | 0 | 0 | 2.57319 | 2.24723 | 0.0 | 0 |
| 6 | 1 | 2006 | 19.8659 | 0.899984 | 0 | 0 | 0 | 5.06752 | 4.23316 | 0.785892 | 0 |
combine(groupby(did_data, :first_treat), nrow)4×2 DataFrame
| Row | first_treat | nrow |
|---|---|---|
| Int64 | Int64 | |
| 1 | 0 | 1572 |
| 2 | 2004 | 714 |
| 3 | 2005 | 498 |
| 4 | 2006 | 216 |
@rtransform! did_data :treated_cohort1 = begin
if :d4 == 1 && :f04 == 1
"d4f04"
elseif :d4 == 1 && :f05 == 1
"d4f05"
elseif :d4 == 1 && :f06 == 1
"d4f06"
else
missing
end
end
@rtransform! did_data :treated_cohort2 = begin
if :d5 == 1 && :f05 == 1
"d5f05"
elseif :d5 == 1 && :f06 == 1
"d5f06"
else
missing
end
end
@rtransform! did_data :treated_cohort3 = begin
if :d6 == 1 && :f06 == 1
"d6f06"
else
missing
end
end
combine(groupby(dropmissing(did_data, :treated_cohort1), :treated_cohort1), :te4 => mean => :mean4)3×2 DataFrame
| Row | treated_cohort1 | mean4 |
|---|---|---|
| String | Float32 | |
| 1 | d4f04 | 3.75709 |
| 2 | d4f05 | 4.01757 |
| 3 | d4f06 | 4.57895 |
combine(groupby(dropmissing(did_data, :treated_cohort2), :treated_cohort2), :te5 => mean => :mean5)
combine(groupby(dropmissing(did_data, :treated_cohort3), :treated_cohort3), :te6 => mean => :mean6)1×2 DataFrame
| Row | treated_cohort3 | mean6 |
|---|---|---|
| String | Float32 | |
| 1 | d6f06 | 1.84886 |
# String columns needed for cohort×time ETWFE dummies
did_data.first_treat_str = string.(did_data.first_treat)
did_data.year_str = string.(did_data.year)
# this replicates Jeff's results with pooled ols or xtreg, with covariate x.
mod = feols(did_data, @formula(y ~ x + first_treat_str & year_str + fe(id) + fe(year)), vcov = Vcov.cluster(:id))
show_regression_html(mod)| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| x | -1.313e-32 | 5.787e-32 | -0.227 | 0.820 |
| first_treat_str: 0 & year_str: 2001 | 0.913 | 0.133 | 6.850 | 7.378e-12 *** |
| first_treat_str: 2004 & year_str: 2001 | -1.124 | 0.159 | -7.086 | 1.381e-12 *** |
| first_treat_str: 2005 & year_str: 2001 | -0.425 | 0.172 | -2.465 | 0.014 * |
| first_treat_str: 2006 & year_str: 2001 | 0.636 | 0.242 | 2.625 | 0.009 ** |
| first_treat_str: 0 & year_str: 2002 | 0.802 | 0.129 | 6.194 | 5.854e-10 *** |
| first_treat_str: 2004 & year_str: 2002 | -1.198 | 0.178 | -6.724 | 1.767e-11 *** |
| first_treat_str: 2005 & year_str: 2002 | -0.291 | 0.181 | -1.610 | 0.107 |
| first_treat_str: 2006 & year_str: 2002 | 0.687 | 0.233 | 2.950 | 0.003 ** |
| first_treat_str: 0 & year_str: 2003 | 0.644 | 0.137 | 4.707 | 2.510e-06 *** |
| first_treat_str: 2004 & year_str: 2003 | -1.187 | 0.168 | -7.073 | 1.512e-12 *** |
| first_treat_str: 2005 & year_str: 2003 | 0.198 | 0.211 | 0.939 | 0.348 |
| first_treat_str: 2006 & year_str: 2003 | 0.345 | 0.260 | 1.324 | 0.186 |
| first_treat_str: 0 & year_str: 2004 | 0.224 | 0.138 | 1.628 | 0.104 |
| first_treat_str: 2004 & year_str: 2004 | 1.611 | 0.205 | 7.860 | 3.832e-15 *** |
| first_treat_str: 2005 & year_str: 2004 | -1.361 | 0.181 | -7.512 | 5.806e-14 *** |
| first_treat_str: 2006 & year_str: 2004 | -0.474 | 0.258 | -1.834 | 0.067 . |
| first_treat_str: 0 & year_str: 2005 | -0.966 | 0.146 | -6.629 | 3.389e-11 *** |
| first_treat_str: 2004 & year_str: 2005 | 1.299 | 0.213 | 6.109 | 1.000e-09 *** |
| first_treat_str: 2005 & year_str: 2005 | 0.916 | 0.223 | 4.102 | 4.092e-05 *** |
| first_treat_str: 2006 & year_str: 2005 | -1.249 | 0.254 | -4.910 | 9.123e-07 *** |
| first_treat_str: 0 & year_str: 2006 | -1.617 | 0.169 | -9.585 | < 2e-16 *** |
| first_treat_str: 2004 & year_str: 2006 | 0.600 | 0.232 | 2.587 | 0.010 ** |
| first_treat_str: 2005 & year_str: 2006 | 0.963 | 0.249 | 3.864 | 1.116e-04 *** |
| first_treat_str: 2006 & year_str: 2006 | 0.055 | 0.354 | 0.155 | 0.877 |
| --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 |
||||
emfx(mod)1×5 DataFrame
| Row | type | estimate | std_error | conf_low | conf_high |
|---|---|---|---|---|---|
| String | Float64 | Float64 | Float64 | Float64 | |
| 1 | ATT | 0.907151 | 0.0582209 | 0.793041 | 1.02126 |
mod_es = emfx(mod, type = "event")
mod_es3×5 DataFrame
| Row | event | estimate | std_error | conf_low | conf_high |
|---|---|---|---|---|---|
| Int64 | Float64 | Float64 | Float64 | Float64 | |
| 1 | 0 | 0.860449 | 0.177864 | 0.511843 | 1.20905 |
| 2 | 1 | 1.13086 | 0.165562 | 0.806369 | 1.45536 |
| 3 | 2 | 0.599837 | 0.231825 | 0.145468 | 1.05421 |
mod_es2 = emfx(mod, type = "calendar")
mod_es23×5 DataFrame
| Row | calendar | estimate | std_error | conf_low | conf_high |
|---|---|---|---|---|---|
| Int64 | Float64 | Float64 | Float64 | Float64 | |
| 1 | 2004 | 1.6105 | 0.20489 | 1.20892 | 2.01208 |
| 2 | 2005 | 1.10755 | 0.122831 | 0.866807 | 1.3483 |
| 3 | 2006 | 0.539101 | 0.0562459 | 0.428862 | 0.649341 |
13.12 Nonlinear ETWFE: Count and Binary Outcomes
ETWFE is not limited to linear outcomes. When \(Y\) is a count or binary variable, the key identifying assumption shifts to Conditional Parallel Trends on the linear index: parallel trends on \(\log E[Y_{it}(\infty)]\) for Poisson, or on \(\text{logit}\, E[Y_{it}(\infty)]\) for logit. This is Wooldridge’s (2023, 2026) CPT assumption stated on \(G^{-1}(E[Y])\).
The correct Wooldridge ETWFE specification for a nonlinear model uses: - Cohort FE (one intercept per treatment cohort, including never-treated): captures selection into treatment - Year FE (common time trend): identified from never-treated units - Post-treatment cohort×year dummies (one per treated cohort per post-treatment year): capture the ATTs on the log scale
Critically, this is a pooled model, not a within-estimator. In the linear Gaussian examples above, unit FE and cohort FE give numerically identical ATTs (Wooldridge 2021). In nonlinear models, however, unit fixed effects raise the incidental-parameters problem and make average partial effects uncomputable — the unit intercepts cannot be averaged out of the nonlinear link. Wooldridge (2023) instead uses cohort intercepts (a Mundlak device), which is what etwfe implements; that is why the cohort-FE requirement matters only for Poisson/logit ETWFE.
13.12.1 Simulated example: staggered count data
We simulate panel data with three treatment cohorts (treated in years 3, 4, 5) and a never-treated group. The true treatment effect is multiplicative: \(\exp(0.4) - 1 \approx 49\%\) increase in counts. Parallel trends holds on the log scale.
Random.seed!(42)
N_pois = 600; Tmax_pois = 6
unit_fe_vals = randn(N_pois) .* 0.3
rows_p = [(id=i, year=t) for i in 1:N_pois for t in 1:Tmax_pois]
df_count = DataFrame(rows_p)
sort!(df_count, [:id, :year])
cohort_grp = ((df_count.id .- 1) .÷ 150) .+ 1
df_count.first_treat = [3, 4, 5, 0][cohort_grp] # 0 = never treated
df_count.treated = (df_count.first_treat .> 0) .& (df_count.year .>= df_count.first_treat)
df_count.unit_fe = unit_fe_vals[df_count.id]
df_count.log_mu = 1.0 .+ 0.2 .* df_count.year .+ df_count.unit_fe .+ 0.4 .* df_count.treated
df_count.count = rand.(Poisson.(exp.(df_count.log_mu)))
combine(groupby(df_count, [:first_treat, :treated]), :count => mean => :mean_count)7×3 DataFrame
| Row | first_treat | treated | mean_count |
|---|---|---|---|
| Int64 | Bool | Float64 | |
| 1 | 0 | false | 5.96222 |
| 2 | 3 | false | 3.73 |
| 3 | 3 | true | 10.5767 |
| 4 | 4 | false | 4.12222 |
| 5 | 4 | true | 11.1311 |
| 6 | 5 | false | 4.54333 |
| 7 | 5 | true | 12.63 |
13.12.2 Poisson ETWFE
etwfe() handles formula construction, cohort FE + year FE, and post-treatment dummy creation automatically. Pass family = "poisson" for count outcomes.
mod_pois = etwfe(df_count, @formula(count ~ 1);
gvar = :first_treat, tvar = :year,
family = "poisson", vcov = Vcov.cluster(:id))ETWFEResult(Panelest Model: poisson
Number of obs: 3600
Converged: true
Iterations: 4
StatsBase.CoefTable(Any[[0.42893919380789136, 0.4165746937859984, 0.42989276015968575, 0.4605410131831185, 0.4641380040987659, 0.3550224365258406, 0.4153499256703512, 0.4622661899383511, 0.42748007385293485], [0.05117575537987214, 0.050643517761621355, 0.05614332541334621, 0.05115065391092361, 0.04380315342946862, 0.050092048474205654, 0.048129097675246306, 0.04711015759871549, 0.043939708401587334], [8.381687590616334, 8.225627132515008, 7.657059089298138, 9.003619269171582, 10.595995214045859, 7.08740104147778, 8.629912999261848, 9.812452632316292, 9.728787226942362], [5.2174165571338964e-17, 1.9417218787529506e-16, 1.9023911860336307e-14, 2.1839652860384976e-19, 3.110150404711567e-26, 1.366539510748217e-12, 6.13986580791824e-18, 9.951975478736554e-23, 2.2728651092911817e-22]], ["Estimate", "Std. Error", "z value", "Pr(>|z|)"], ["_D_g3_t3", "_D_g3_t4", "_D_g3_t5", "_D_g3_t6", "_D_g4_t4", "_D_g4_t5", "_D_g4_t6", "_D_g5_t5", "_D_g5_t6"], 4, 3), ["_D_g3_t3", "_D_g3_t4", "_D_g3_t5", "_D_g3_t6", "_D_g4_t4", "_D_g4_t5", "_D_g4_t6", "_D_g5_t5", "_D_g5_t6"], [3, 4, 5], 1:6, :first_treat, :year, "poisson")att = emfx(mod_pois)
@printf("ATT (log scale): %.4f (SE = %.4f)\n", att.estimate[1], att.std_error[1])
@printf("IRR - 1: %.4f (true ≈ 0.492)\n", exp(att.estimate[1]) - 1)ATT (log scale): 0.4289 (SE = 0.0298)
IRR - 1: 0.5356 (true ≈ 0.492)The ATT is on the log scale (log incidence rate ratio). Exponentiate and subtract 1 for the proportional increase in counts.
13.12.3 Event study
mod_pois_es = emfx(mod_pois, type = "event")
fig_p = Figure()
ax_p = Axis(fig_p[1, 1],
xlabel = "Years post treatment",
ylabel = "ATT (log scale)",
title = "Poisson ETWFE event study")
hlines!(ax_p, 0, color = :black, linewidth = 1)
rangebars!(ax_p, mod_pois_es.event,
mod_pois_es.conf_low, mod_pois_es.conf_high, color = :darkcyan)
scatter!(ax_p, mod_pois_es.event, mod_pois_es.estimate, color = :darkcyan)
fig_p
13.12.4 Comparison: linear ETWFE on log(count + 1)
df_count.log_count = log.(df_count.count .+ 1)
mod_lin = etwfe(df_count, @formula(log_count ~ 1);
gvar = :first_treat, tvar = :year,
vcov = Vcov.cluster(:id))
emfx(mod_lin)1×5 DataFrame
| Row | type | estimate | std_error | conf_low | conf_high |
|---|---|---|---|---|---|
| String | Float64 | Float64 | Float64 | Float64 | |
| 1 | ATT | 0.384516 | 0.0283914 | 0.32887 | 0.440162 |
The linear model estimates the ATT on the \(\log(Y+1)\) scale — a different and less interpretable quantity than the Poisson log IRR.
13.13 Spatial Interference
Everything in this chapter so far assumes SUTVA: one unit’s outcome does not depend on another unit’s treatment. That is not always plausible. A treated municipality may affect deforestation in nearby untreated municipalities. A vaccinated household may reduce transmission to nearby households. A labor-market policy in one commuting zone may change flows to its neighbors. With this kind of spatial spillover, the usual DiD estimand no longer has the interpretation we want. Xu (2023) shows that ignoring interference can produce an estimand that is neither a direct effect nor a spillover effect.
Xu (2023, 2026) develops a doubly robust DiD that keeps the identifying logic of conditional parallel trends but adds an exposure mapping \(G_{it} = G(i, W_{-it})\) for unit \(i\)’s neighborhood treatment status. The estimand is the direct ATT at exposure level \(g\),
\[ \tau_g(t, c) = \frac{1}{|S_M|} \sum_{i \in S_M} \mathbb{E}[y_{it}(c, g) - y_{it}(\infty, g) \mid z_i, C_i = c, G_{it} = g], \]
where \(C_i\) is unit \(i\)’s first treatment period (so \(\{C_i > t\}\) is the not-yet-directly-treated comparison group), \(S_M = \{C_i = c\} \cup \{C_i > t\}\), and \(g\) is a chosen exposure level. The DR plug-in averages three pieces over \(S_M\): an IPW term from the treated cohort, an IPW term from the not-yet-treated, and a regression-imputation term, with three propensity models (\(\eta_{tc}\) for cohort, \(\eta_{tcg}\) and \(\eta_{t\infty g}\) for exposure) and two outcome-change regressions. It is consistent if either all three propensities or both outcome models are correctly specified.
The companion package DidInterference.jl implements this. The 2×2 base case (Xu 2023):
using DidInterference, DataFrames
res = did_int_2x2(panel;
yname = :Y_post,
yname_pre = :Y_pre,
treat = :W,
exposure = :G,
g = 1,
covariates = [:z1, :z2],
trim = 0.01) # Xu (2026) uses 0.01 in the Brazil application
println(res.estimate, " ", res.ci)For staggered adoption (Xu 2026), did_int_staggered() loops over (cohort, time) cells with \(t \geq c\), restricts to \(S_M\) in each cell, fits the DR estimator, and aggregates across cells using joint-IF stacking (per-cell IFs share the never-treated comparison group, so independence-style SEs underestimate uncertainty noticeably). An R port with the same interface is available as didint; its Brazil Amazon Lista de Municípios Prioritários vignette replicates Section III of Xu (2026) using the public Assunção-McMillan-Murphy-Souza-Rodrigues replication archive on Zenodo.
13.14 Persistent Outcomes and Heterogeneous Dynamics
Standard event-study TWFE regressions like
\[ Y_{it} = \alpha_i + \gamma_t + \sum_{j} D_{it}^j \delta_j + X_{it}'\beta + U_{it} \]
implicitly assume the residual has no serial dependence once unit and time fixed effects are absorbed. When outcomes are genuinely persistent — earnings, employment, consumption, anything with habits or adjustment costs — that assumption fails. The event-time dummies absorb persistence on top of the true causal effect, producing spurious pre-trends and biased post-treatment estimates whose bias grows geometrically with the event-time horizon (Botosaru and Liu 2025, Figure 1).
Botosaru and Liu (2025) introduce a dynamic panel with correlated random coefficients that handles both persistence and unit-level heterogeneity in dynamic responses:
\[ Y_{it} = \rho_Y Y_{i,t-1} + \alpha_i + \sum_j D_{it}^j \delta_{ij} + X_{it}'\beta + U_{it}, \]
with a parsimonious AR(1) on the event-time effects to keep dimensionality manageable:
\[ \delta_{ij} = \rho_\delta \delta_{i,j-1} + \varepsilon_{ij}, \quad j \geq 1. \]
The latent \(\lambda_i = (\alpha_i, \delta_{i0})\) is a unit-specific correlated random coefficient. A two-step semiparametric estimator: step 1 is quasi-maximum likelihood for the common parameters under a Gaussian working assumption on \(\lambda_i\) (consistent under misspecification); step 2 is Tweedie / Gaussian-conjugate empirical Bayes for the unit-level posterior trajectories \(\{\delta_{i,j}\}_{j=0}^J\).
A companion note (Botosaru and Liu 2026) adds a homogeneous-feedback extension: covariates \(X_{it}\) are allowed to adjust endogenously to past \(Y\) and treatment. Under the assumption that the covariate adjustment rule does not depend on \(\lambda_i\) given the observable history, the likelihood factors into a structural piece and a feedback piece, yielding a clean decomposition of dynamic treatment effects into direct (through \(\delta_{i,j}\)) and indirect (through covariate feedback) components.
The package TVHTE.jl implements both papers:
using TVHTE
# Fit on a panel with staggered cohorts and a covariate
fit = tvhte(panel_Y, baseline_Y; t0 = cohort, J = max_event_time, X = panel_X)
# Feedback model + direct/indirect counterfactual decomposition
fb = fit_feedback(panel_Y, baseline_Y, panel_X, baseline_X)
cf = simulate_counterfactual(fit, fb, alt_cohort)An R port with the same API is at tvhte; both packages have deployed docs at https://xiangao.github.io/TVHTE.jl/ and https://xiangao.github.io/tvhte/.
Synthetic control, synthetic DiD, and TASC are closely related enough that we treat them together in the next design chapter.