Call:
lm(formula = mpg ~ disp + hp + wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.891 -1.640 -0.172 1.061 5.861
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.105505 2.110815 17.579 < 2e-16 ***
disp -0.000937 0.010350 -0.091 0.92851
hp -0.031157 0.011436 -2.724 0.01097 *
wt -3.800891 1.066191 -3.565 0.00133 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.639 on 28 degrees of freedom
Multiple R-squared: 0.8268, Adjusted R-squared: 0.8083
F-statistic: 44.57 on 3 and 28 DF, p-value: 8.65e-111 OLS
A linear model with \(n\) observations and \(k\) regressors can be written as (in vector forms) \[ \bf y=X\beta+u \]
The idea of least-squares is to choose \(\beta\) to minimize the residual sum of squares (\(SSR\)),
\[ SSR(\beta) = \bf (y-X\beta)'(y-X\beta) = \bf y'y-2\beta'X'y+\beta'X'X\beta \]
The first-order condition to minimize \(SSR\) are: \[ \frac{\partial (SSR)}{\partial \beta} = \bf -2X'y+2X'X\beta=0\]
This generates the so-called normal equations \[\bf (X'X)\beta=X'y\]
Therefore, Ordinary Least Squares (OLS) estimator of \(\beta\) is \[\bf \hat \beta=(X'X)^{-1}X'y\]
1.1 Fitness of OLS
We can see \(y\) vector as the part explained by the regression and the unexplained (residual) part, \[ \bf y=\hat y+\hat u=X\hat\beta+\hat u\] where \(\hat u\) is the OLS residual. Because the residual is orthogonal to the fitted values, \(\bf \hat y' \hat u=0\), so the cross term drops: \[\bf y'y=(\hat y+\hat u)'(\hat y +\hat u)=\hat y' \hat y +\hat u'\hat u=\hat\beta'X'X\hat\beta +\hat u'\hat u \]
Subtracting \(n\bar y^2\) (\(\bar y\) is the sample mean) from both sides, and assuming the regression includes an intercept (so that \(\bar{\hat y}=\bar y\) and the residuals sum to zero, which is what makes this centered decomposition and the \(R^2\) interpretation below hold), \[ \bf y'y-n\bar y^2=(\hat\beta'X'X\hat\beta-n\bar y^2) +\hat u'\hat u \]
We decompose the total sum of squares into two parts: sum of squares due to error (noise), and sum of squares explained by the linear regression.
The \(R^2\) is defined by \[R^2=1-\frac{SSR}{SST}\]
\(SST\) is the total (centered) sum of squares of \(y\), \(\bf y'y-n\bar y^2 = \sum_t (y_t-\bar y)^2\).
\(R^2\) is simply the proportion of the variation of \(Y\) that can be attributed to the variation of \(X\). \(R^2\), however, will never decrease with the addition of any variable to the set of regressors. \(R^2\) stays exactly the same only in the knife-edge case that the added variable is orthogonal to the current residuals; in practice it always rises a little, even for an irrelevant variable. The adjusted \(R^2\), however, takes account of the addition of any new regressors:
\[\bar R^2=1-\frac{SSR/(n-k)}{SST/(n-1)}\]
1.2 Example
Let’s look at an example of OLS of car’s mpg on disp, hp and wt.
1.3 The Geometry of Least Squares
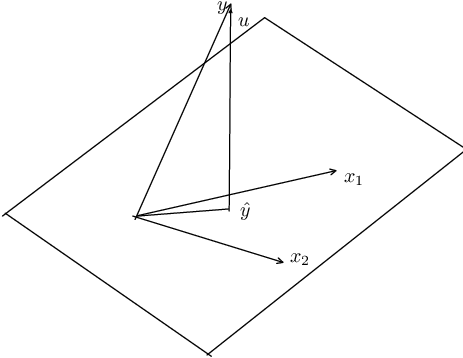
For simplicity, let’s assume there are two explanatory variables \(x_1\) and \(x_2\). \(x_1\) and \(x_2\) form a plane. What OLS does is to project \(y\) onto this plane.
In mathematical terms, all linear combinations of these two vectors define a two-dimensional subspace of Euclidean space \({\rm \bf E}^n\). This is called the column space of \(\bf X\). The least-square principle is to choose \(\beta\) to make \(\hat y\), which belongs to the subspace of \(\bf X\), as close as possible to \(y\).
When we estimate a linear regression model, we map the \(y\) into a vector of fitted values \(\bf X \hat \beta\) and a vector of residuals \(\bf \hat u =y-X \hat \beta\). Geometrically, these are examples of orthogonal projections. A projection is a mapping that takes each point of \({\rm \bf E}^n\) into a point in a subspace of \({\rm \bf E}^n\). An orthogonal projection maps any point into the point of the subspace that is closest to it.
An orthogonal projection can be performed by premultiplying the vector to be projected by a projection matrix. In the case of OLS, the two projection matrices that yield the vector of fitted values and the vector of residuals, are \[\bf P_X = \bf X(X'X)^{-1}X' \] \[\bf M_X = \bf I-P_X = I- \bf X(X'X)^{-1}X'\]
From this, we see that the effects of two projection matrices. \[\bf P_X y = \bf X \hat \beta =\bf \hat y \] \[\bf M_X y = \bf (I-P_X)y = y- \bf P_X y = y-X \hat \beta =\hat u \]
That is, \(\bf P_X y\) projects \(\bf y\) onto \(\bf X\) and makes it \(\bf \hat y\); \(\bf M_X y\) makes it \(\bf \hat u\).
In the picture, that corresponds to the fact that the projection of \(\bf y\) onto the plane of \(\bf X\) creates two parts: \(\bf \hat y\) and \(\bf \hat u\).
1.4 Properties of OLS estimator
1.4.1 Unbiasedness
In a linear model \[ \bf y=X\beta+u, \] the OLS estimator is \[ \bf \hat \beta=(X'X)^{-1}X'y \]
Since \(\bf y=X \beta+u\),
\[ \bf \hat \beta=\beta + (X'X)^{-1}X'u. \]
This makes \[ {\rm E} \bf (\hat \beta | X)=\beta + (X'X)^{-1}X'{\rm E} (u|X). \]
The condition that makes the OLS estimator unbiased is: \[ {\rm E} \bf (u|X)=0, \]
that is, all explanatory variables which form the columns of \(\bf X\) are exogenous. This condition is weaker than the independence condition that \(u\) and \(X\) are independent. This says that given \(\bf X\), the expected value of \(\bf u\) is zero; it implies that the model is correctly specified. That is, \(\bf y\) is a linear function of \(\bf X\).
In the context of cross-sectional data, this assumption is plausible. However, when we have time series data, the assumption becomes strong, because it assumes that the entire series of \(\bf X\) has no relationship with the error term. In a time series context, this is hard to satisfy. The OLS estimator is biased if this condition is not satisfied.
For example, suppose we have a model
\[ y_t = \beta_1 + \beta_2 y_{t-1} + u_t, \quad u_t \sim {\rm IID} (0, \sigma^2). \]
In this simple model, even if we assume that \(y_{t-1}\) and \(u_t\) are uncorrelated, OLS estimator is still biased. That is because \({\rm E} \bf (u|X)=0\) is not satisfied: \(y_{t-1}\) depends on \(u_{t-1}\), \(u_{t-2}\) and so on.
There is a weaker condition: \[ {\rm E} \bf (X u)=0, \]
Once we know that the model is correctly specified, then this equation can be used to derive results, such as GMM estimators.
1.4.2 Consistency
For OLS estimator to be consistent, a much weaker condition is needed: \[ {\rm E} (u_t|X_t)=0, \]
This condition is much weaker since it only assumes that the mean of current error term does not depend on the current predictors. Even a model with lagged dependent variable can easily satisfy this condition. This condition is called contemporaneous exogeneity (regressors are contemporaneously uncorrelated with the error). This is distinct from and weaker than strict exogeneity \(E[u \mid X] = 0\), but it is itself stronger than predeterminedness, which only requires \(X_t\) to be orthogonal to the current and future errors (\(E[u_t \mid \mathcal F_{t-1}] = 0\) where \(X_t\) is measurable with respect to \(\mathcal F_{t-1}\)) while allowing correlation with past errors – the relevant condition, for example, in models with a lagged dependent variable. So in the time series example, OLS estimator is biased, but can be consistent, if we are willing to assume no contemporaneous correlation.
Note: general linear hypothesis testing, the Chow test for structural change, and heteroskedasticity- and autocorrelation-consistent (HAC) standard errors (White, Newey-West) are all standard OLS extensions, but are covered in the Maximum Likelihood chapter alongside this guide’s other estimation-inference material rather than repeated here.