2 Five Estimands on One DGP
Before choosing an estimator, we need to know the estimand. ATE, ATT, LATE, CATE and QTE are not five ways to estimate the same object. They are five different objects. Sometimes they are numerically close, but that is a feature of the data-generating process, not a general result.
Here I use one simulated data set so we can calculate all of them. The simulation is useful because we observe both potential outcomes. In real data we do not, which is exactly why identification assumptions matter.
2.1 The data-generating process
Each person has an observed covariate \(X_i\), an unobserved type \(U_i\), and a binary treatment \(D_i\). The instrument \(Z_i\) is a random offer. It changes the probability of treatment, but it has no direct effect on the outcome.
set.seed(42)
n <- 20000
X <- runif(n, 0, 1) # observed covariate, in [0,1]
U <- rnorm(n) # latent type, unobserved
Z <- rbinom(n, 1, 0.5) # random instrument
# Treatment assignment: depends on Z (the instrument) and U (selection on type)
# Higher U → more likely to take treatment regardless of Z (always-takers)
# Lower U → less likely to take treatment regardless of Z (never-takers)
# Middle U → responsive to Z (compliers)
pD0 <- pmin(pmax(0.10 + 0.20 * U, 0), 1) # P(D=1 | Z=0, U)
pD1 <- pmin(pmax(0.10 + 0.20 * U + 0.50, 0), 1) # P(D=1 | Z=1, U) — adds 0.50
# One latent draw V per person, thresholded against both probabilities.
# Since pD1 >= pD0, V < pD0 implies V < pD1, so D1 >= D0 for every unit:
# monotonicity (no defiers) holds by construction, as the LATE theorem requires.
V <- runif(n)
D0 <- as.integer(V < pD0) # potential treatment if not offered slot
D1 <- as.integer(V < pD1) # potential treatment if offered slot
D <- ifelse(Z == 1, D1, D0)
# Heterogeneous treatment effect: depends on X
# Y(d) = baseline + d * tau(X) + 0.3 * U + noise
tau_fn <- function(x) 1.0 + 2.0 * x # the true individual treatment effect
Y0 <- 0.5 * X + 0.3 * U + rnorm(n)
Y1 <- Y0 + tau_fn(X)
Y <- ifelse(D == 1, Y1, Y0)
df <- data.frame(X = X, Z = Z, D = D, Y = Y)
head(df) X Z D Y
1 0.9148060 1 1 4.1619422
2 0.9370754 0 0 -0.8962833
3 0.2861395 1 1 1.7657727
4 0.8304476 1 1 3.0306957
5 0.6417455 0 0 0.1362524
6 0.5190959 0 0 -0.2396664In the simulated data we have Y0 and Y1 for every observation. That lets us calculate the true estimands directly. With real data, each observation only reveals one potential outcome.
2.2 The five estimands
2.2.1 ATE — average treatment effect
\[ \text{ATE} = \mathbb{E}[Y(1) - Y(0)] \]
ATE is the mean effect in the whole population. It compares the mean outcome if everyone were treated with the mean outcome if nobody were treated.
ATE (population mean of Y1 - Y0) = 1.996# Theoretical ATE: integral of (1 + 2x) over Uniform[0,1] = 1 + 1 = 2
cat("Theoretical ATE = integral(1 + 2x)dx on [0,1] = 2.000\n")Theoretical ATE = integral(1 + 2x)dx on [0,1] = 2.0002.2.2 ATT — average treatment effect on the treated
\[ \text{ATT} = \mathbb{E}[Y(1) - Y(0) \mid D = 1] \]
ATT is the mean effect for the units that actually took treatment. It differs from ATE when treatment selection is related to treatment-effect heterogeneity.
ATT (mean of Y1-Y0 conditional on D=1) = 1.995Here ATT is close to ATE – and in fact the two are analytically identical in this DGP, exactly \(2.0\) in the population; the estimates above only differ by finite-sample simulation noise, not by any true gap between the estimands. The reason is mechanical: the individual treatment effect \(\tau_i = 1+2X_i\) depends only on \(X_i\), while selection into treatment depends on \(U_i\) (and the instrument \(Z_i\) below), and \(X_i\) is generated independently of \(U_i\) and \(Z_i\). Since treatment-effect heterogeneity is unrelated to who selects into treatment or who complies with the instrument, averaging \(\tau_i\) over the treated subpopulation or over compliers gives the same population average as over everyone – hence ATE = ATT = LATE = \(2.0\) exactly here. If selection (or compliance) also depended on \(X\), these estimands would diverge, since ATE, ATT, and LATE are different averages of \(\tau_i\) across different, non-identical subpopulations.
2.2.3 LATE — local average treatment effect (Imbens-Angrist)
\[ \text{LATE} = \mathbb{E}[Y(1) - Y(0) \mid D(1) > D(0)] \]
LATE is the mean effect for compliers, the units whose treatment status is changed by the instrument. Under the usual IV assumptions, the Wald estimator identifies this effect, not the ATE.
LATE (mean of Y1-Y0 conditional on complier status) = 1.999Share of compliers: 0.456Wald IV estimate (should match LATE): 1.949With heterogeneous effects, IV averages over the people moved by the instrument. In this example the Wald estimate matches the complier mean because \(Z\) changes treatment only for that group.
2.2.4 CATE — conditional average treatment effect
\[ \text{CATE}(x) = \mathbb{E}[Y(1) - Y(0) \mid X = x] \]
CATE keeps \(X\) in the estimand. In this DGP, CATE(\(x\)) is simply \(\tau(x)=1+2x\).
nbins <- 20
breaks <- seq(0, 1, length.out = nbins + 1)
centers <- (breaks[-1] + breaks[-(nbins + 1)]) / 2
bin_idx <- cut(X, breaks = breaks, include.lowest = TRUE, labels = FALSE)
cate_est <- tapply(Y1 - Y0, bin_idx, mean)
cat(sprintf("CATE at x=%.3f: estimated %.2f, true %.2f\n",
centers[4], cate_est[4], tau_fn(centers[4])))CATE at x=0.175: estimated 1.35, true 1.35CATE at x=0.775: estimated 2.55, true 2.552.2.5 QTE — quantile treatment effect
\[ \text{QTE}(q) = F^{-1}_{Y(1)}(q) - F^{-1}_{Y(0)}(q) \]
QTE compares the two marginal outcome distributions. It is the difference between a quantile under treatment and the same quantile under control. It does not follow the same person across the two potential outcomes.
QTE(0.10) = 1.709QTE(0.50) = 2.009QTE(0.90) = 2.2832.3 All five estimands on one plot
df_cate <- data.frame(x = centers, cate = as.numeric(cate_est),
true_tau = tau_fn(centers))
df_qte <- data.frame(q = qte_grid, qte = as.numeric(qte_est))
p1 <- ggplot(df_cate, aes(x = x)) +
geom_line(aes(y = cate, colour = "CATE(x)"), linewidth = 1.2) +
geom_line(aes(y = true_tau, colour = "True τ(x)"),
linetype = "dotted", linewidth = 1) +
geom_hline(aes(yintercept = ate_true, colour = "ATE"), linetype = "dashed") +
geom_hline(aes(yintercept = att_true, colour = "ATT"), linetype = "dashed") +
geom_hline(aes(yintercept = late_true, colour = "LATE"), linetype = "dashed") +
scale_colour_manual(values = c(
"CATE(x)" = "#c0392b", "True τ(x)" = "#e74c3c",
"ATE" = "#2c3e50", "ATT" = "#2980b9", "LATE" = "#27ae60"
)) +
labs(x = "X (covariate)", y = "Effect", colour = NULL,
title = "CATE(x) vs scalar estimands") +
theme_minimal() +
theme(legend.position = "bottom")
p2 <- ggplot(df_qte, aes(x = q, y = qte)) +
geom_line(colour = "#8e44ad", linewidth = 1.2) +
geom_hline(yintercept = ate_true, linetype = "dashed", colour = "#2c3e50") +
annotate("text", x = 0.07, y = ate_true + 0.06, label = "ATE",
colour = "#2c3e50", size = 3) +
labs(x = "Quantile q", y = "QTE(q)",
title = "QTE — distribution-level effect") +
theme_minimal()
grid.arrange(p1, p2, ncol = 2)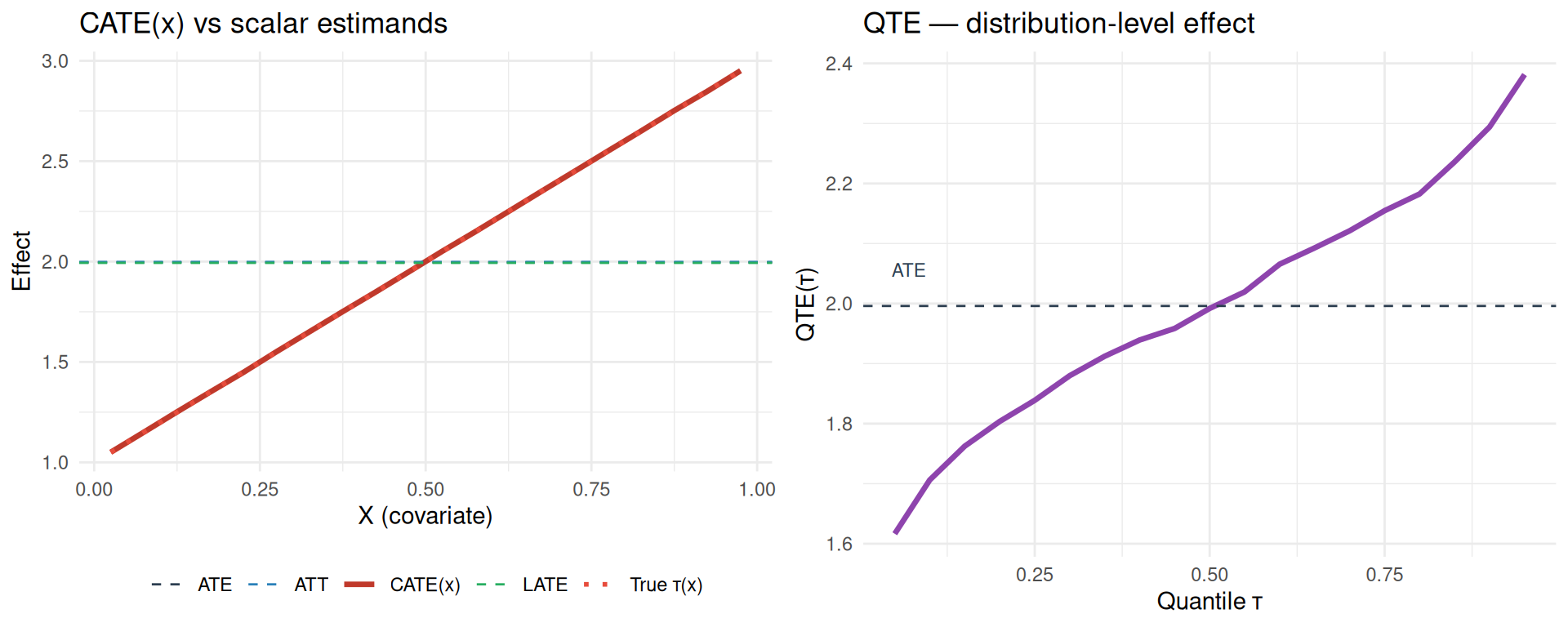
The left panel shows why the scalar estimands can differ. ATE averages \(\tau(x)\) over the whole population. ATT averages it over the treated. LATE averages it over compliers. CATE does not collapse the curve.
QTE, in the right panel, is different again. It describes how the treatment changes the outcome distribution. It is not a conditional treatment effect as a function of \(X\).
2.4 When the estimands differ
In the first DGP the scalar estimands are close because:
- \(X\) is uniform on [0, 1] (so ATE = average of τ over uniform \(X\) = 2)
- Treatment selection is on \(U\) (unobserved type), not \(X\) (which drives τ), so ATT ≈ ATE
- The instrument shifts compliers uniformly across \(X\), so LATE ≈ ATE
If treatment selection depends on the effect modifier, the numbers separate. Here I make high-\(X\) units more likely to take treatment:
set.seed(7)
n2 <- 20000
X2 <- runif(n2, 0, 1)
U2 <- rnorm(n2)
Z2 <- rbinom(n2, 1, 0.5)
# High X → much more likely to take treatment (selection on X, the modifier)
pD0_2 <- pmin(pmax(0.10 + 0.20 * U2 + 0.6 * X2, 0), 1)
pD1_2 <- pmin(pmax(pD0_2 + 0.50, 0), 1)
V2 <- runif(n2) # shared draw → D1_2 >= D0_2, no defiers
D0_2 <- as.integer(V2 < pD0_2)
D1_2 <- as.integer(V2 < pD1_2)
D2 <- ifelse(Z2 == 1, D1_2, D0_2)
Y0_2 <- 0.5 * X2 + 0.3 * U2 + rnorm(n2)
Y1_2 <- Y0_2 + tau_fn(X2)
Y2 <- ifelse(D2 == 1, Y1_2, Y0_2)
ate2 <- mean(Y1_2 - Y0_2)
att2 <- mean(Y1_2[D2 == 1] - Y0_2[D2 == 1])
compliers2 <- (D1_2 == 1) & (D0_2 == 0)
late2 <- mean(Y1_2[compliers2] - Y0_2[compliers2])
cat("Selection-on-X DGP:\n")Selection-on-X DGP: ATE = 2.001 ATT = 2.124 (now higher: treated have higher X → larger τ) LATE = 1.926 (compliers' mean X drives this)Now ATT is larger than ATE. The treated group has higher \(X\), and high \(X\) means a larger treatment effect. In this case reporting ATE or ATT changes the substantive answer.
2.5 Which estimand should you choose?
The estimand should come from the research question:
| Policy question | Right estimand |
|---|---|
| “What if we treated everyone?” | ATE |
| “What did treating the currently-treated achieve?” | ATT |
| “What can the instrument tell us?” | LATE |
| “Who benefits most?” | CATE(\(x\)) |
| “Does the effect vary across the outcome distribution?” | QTE(\(q\)) |
| “What is the distribution of individual effects?” | Often unidentifiable; bounds required |
It is fine for one paper to report more than one estimand, as long as each is named correctly. What is not fine is to report the coefficient that is easiest to estimate and call it “the causal effect.”
2.6 Summary
- ATE, ATT and LATE are different averages of the individual treatment effect.
- CATE(\(x\)) keeps heterogeneity by covariates. QTE(\(q\)) describes changes in the outcome distribution.
- With heterogeneous effects, IV estimates LATE. It should not be described as ATE unless extra assumptions justify that interpretation. This is the clean case with no covariates. Once we add covariates linearly to 2SLS, even LATE needs a rich covariates condition that is rarely defended. See Blandhol et al. (2025) and the IV chapter section “When 2SLS with Covariates Is Actually LATE”.
- Estimator choice comes after the estimand is fixed.